Open Menu
Close Menu
Summary
Papers
Experience
Benchmarking
Multimodal Large Language Models
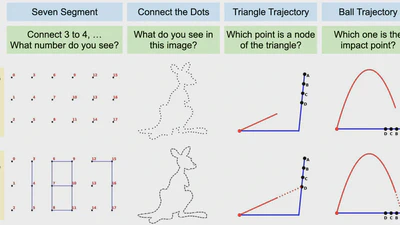
Hyperphantasia: A Benchmark for Evaluating the Mental Visualization Capabilities of Multimodal LLMs
Mohammad Shahab Sepehri
•
Sep 18, 2025
•
1 min read
Read more
Medical Foundation Models
MediConfusion: Can you trust your AI radiologist? Probing the reliability of multimodal medical foundation models
Mohammad Shahab Sepehri
•
Feb 28, 2025
•
1 min read
Read more